Automated PDC Drill Bit Dull Grading
Case Study — Cutter-Level Granularity Through Computer Vision
The Problem
Evaluating PDC drill bit wear has traditionally been a manual, time-consuming process plagued by subjectivity. Dull grading depends on the experience and judgment of individual evaluators — leading to inconsistent data that is difficult to use in the aggregate.
For bit manufacturers, this is a critical bottleneck. Without reliable, granular wear data tied back to specific cutters, it's nearly impossible to make data-driven decisions about the next design iteration.
FloLink's Approach
We developed a two-stage computer vision pipeline that fully automates the dull grading process — from raw photos to a structured, queryable database — with cutter-level granularity.
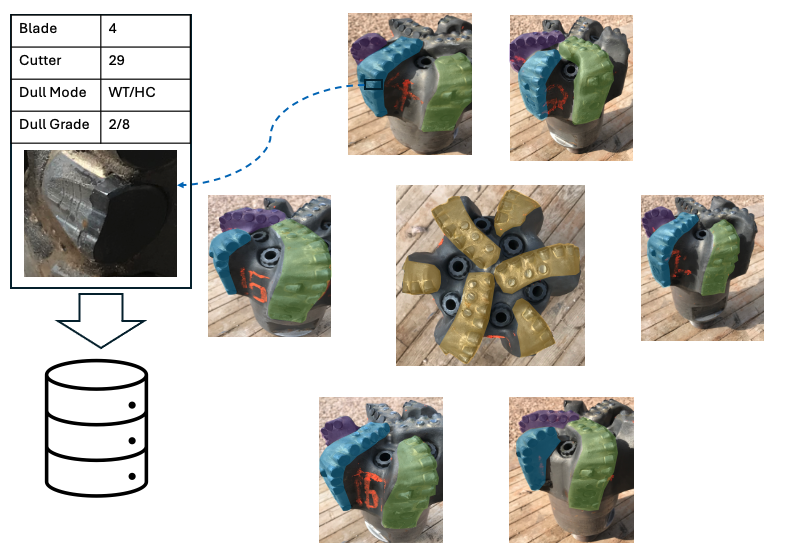
Stage 1 — Blade & Cutter Segmentation
A segmentation model, trained exclusively on each client's own structured PDC bit dull photos, automatically identifies and isolates individual blades and cutters from full-bit images.
- Accepts standard dull photos taken in the field — no special equipment needed
- Segments each blade and extracts individual cutter crops
- Handles varying lighting, angles, and bit conditions
Stage 2 — Wear Mode Classification
Each extracted cutter image is analyzed by a second computer vision model trained specifically on cutter failure types and wear modes.
- Classifies wear mode for every cutter on the bit
- Assigns a dull grade per cutter — not just a single grade for the entire bit
- Results are automatically indexed and uploaded to a structured database
Data Privacy & Model Architecture
Our client's data privacy is our number one priority — beyond any fancy ML bells and whistles. Every machine learning module is trained using each client's data exclusively, without it ever seeing proprietary data from other clients.
Our proprietary machine learning backbone, unlike other similar solutions, is architected to not require any training data aside from each client's specific data. There is no shared dataset, no cross-client model, and no ambiguity about who owns the data or the resulting model.
Client-Isolated Training
Each ML model is trained solely on a single client's data — no co-mingling, no shared training pools, no exceptions.
Proprietary Backbone
Our ML backbone is purpose-built to deliver strong performance using only each client's dataset — no dependency on external or third-party training data.
Full Data Ownership
Clients retain full ownership of their data and the models trained on it. Your data never leaves your control.
Key Results
Cutter-Level Dull Grade Data
Extremely granular wear data indexable to each individual cutter — enabling bit manufacturers to correlate specific cutter performance against bit design parameters and real drilling data for more effective design iteration.
Objective & Consistent
Eliminated the subjectivity inherent in manual dull grading. The resulting data is consistent, repeatable, and usable in the aggregate — unlike human-graded data where evaluator bias makes large-scale analysis unreliable.
80% Reduction in Evaluation Time
Automated pipeline replaces many man-hours of manual photo review, interpretation, and data entry — freeing up engineering time for higher-value analysis.
Have a specialized industrial vision challenge?
Our pre-built model catalog covers a broad range of industrial vision use cases. For challenges requiring a bespoke pipeline — like this one — we scope and deliver custom systems alongside the catalog, with your data privacy guaranteed throughout.
Talk to an Engineer